
欧美888
- 发布日期:2025-12-11 23:36 点击次数:129
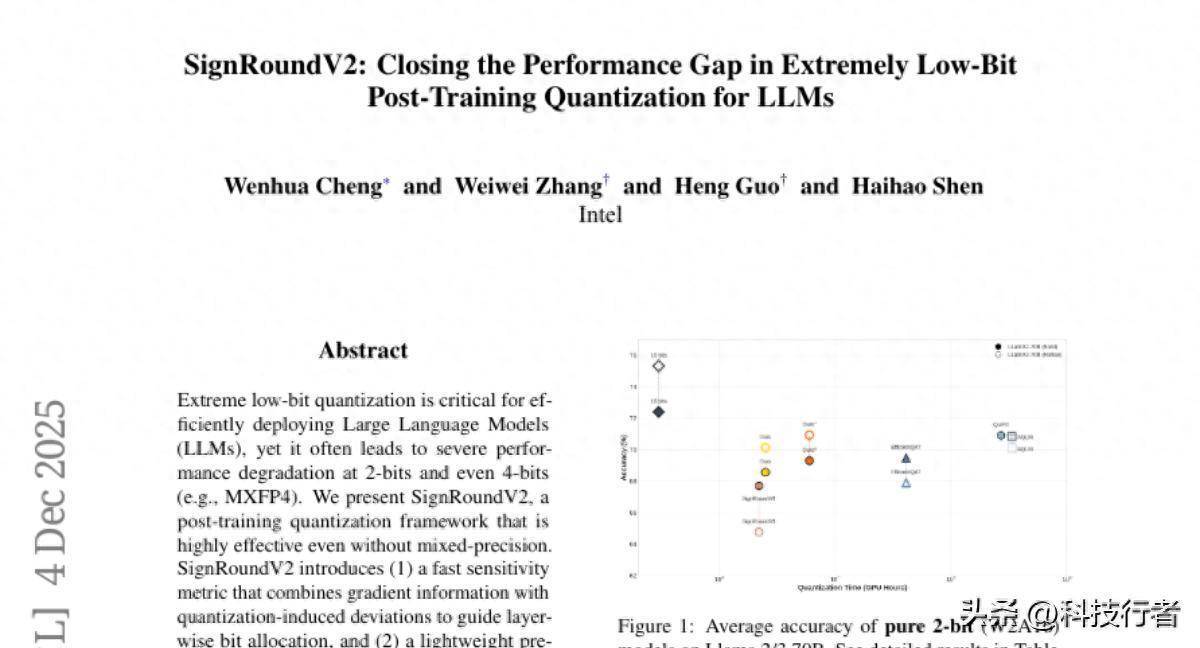
这项由英特尔公司程文采、张蔚蔚、郭恒和沈海浩等盘考东谈主员完成的盘考发表于2025年12月,发布在arXiv预印本平台(论文编号:arXiv:2512.04746v1)。感兴趣的读者不错通过该编号查询完整论文。
当下,东谈主工智能大模子就像一个学问富足但体型雄壮的巨东谈主,领极端十亿甚而千亿个参数,大要报恩各式问题、编写代码、勾通多种讲话。然则,这些模子的"身材"着实太雄壮了,就像要把一头大象搬进小轿车一样困难。普通的电脑、手机甚而一些专科开辟齐难以承载如斯雄壮的模子,更无谓说让它们快速运行了。这就好比你想在家里养一头大象,但你的屋子独一几十平日米,澄澈不本质。
为了处理这个问题,科学家们想出了一种叫作念"量化"的时候,就像把大象的体重减轻,让它大要住进普通屋子里。传统的量化时候就像给大象节食,天然大要减轻分量,但经常会让大象变得朽迈,失去原来的智商。而英特尔的盘考团队最新提议的SignRoundV2时候,则像是找到了一种神奇的减肥方法,既能让大象大幅瘦身,又能保执它原有的力量和聪敏。
这项盘考的创新之处在于提议了一种全新的"明锐性测量"方法。若是把大模子比作一个复杂的机器,那么这个机器的每个零件对举座性能的影响齐不相易。有些零件特别要道,就像汽车的发动机,稍有损坏就会影响整车性能;而有些零件相对次要,就像车内的庇荫品,即使简化也不会影响基本功能。SignRoundV2时候大要精准识别出模子中的"发动机"和"庇荫品",对费事部分保执高精度,对次要部分进行激进压缩,从而完了举座的最优均衡。
盘考团队还开发了一种智能的"预调优搜索"时候,这就像在厚爱装修屋子之前先作念一个翔实的狡计图。传统方法经常是平直动手装修,收尾可能需要反复修改,既败坏时刻又影响质地。而SignRoundV2会在厚爱优化之前先进行一次快速的探索,找到最好的肇始点,然后再进行邃密休养。这种方法不仅提高了最终效果,还大大缩短了计算老本。
一、创新性的明锐性测量时候
传统的模子压缩时候濒临着一个根人性的挑战:如何准确判断模子中每一层的费事进度。这就好比一个复杂的交响乐团,每个乐器的作用齐不同,有些是主旋律,有些是伴奏,若是盲目地让总共乐器齐减小音量,总共这个词献技的效果势必大打扣头。
以往的时候主要依赖于二阶信息(比如海塞矩阵),这就像通过不雅察乐器的复杂度来判断其费事性。然则,这种方法有一个致命颓势:它假定模子面前仍是处于最优状态,梯度接近于零。但在量化历程中,模子会发生权贵变化,这个假定经常不竖立。就好比你在休养交响乐团时,假定每个乐手齐仍是在无缺演奏,但内容上他们可能正在适合新的曲谱。
SignRoundV2提议的DeltaLoss方法接纳了一种愈加直不雅和有用的计策。它使用一阶泰勒张开来平直估算量化对最终耗费的影响。具体来说,关于任何一层,它司帐算该层量化前后的参数各异,然后结合梯度信息来瞻望这种变化对举座性能的影响。这种方法的公式不错简化为:耗费变化约等于梯度与参数变化的点积。
更形象地说,这就像一个警告丰富的乐队引导,他不仅要不雅察每个乐器的演奏技能,还要听取它们对举座音乐效果的孝顺。当某个小提琴手稍稍改动演奏方式时,引导大要立即判断这种改动是让音乐愈加融合照旧产生了不融合音。DeltaLoss即是这么一位"智能引导",它大要准确瞻望每一层的量化对举座模子性能的具体影响。
在内容期骗中,盘考团队发现传统方法频频出现误判。举例,某些看起来不费事的层内容上对模子的举座发达存着要道影响,而一些看似复杂的层反而不错承受更激进的压缩。DeltaLoss方法通过商量量化引起的内容参数偏差和梯度信息,大要更准确地识别出这些"瞒哄的要道层"。
为了减少计算支拨,盘考团队在内容完了中主要关怀激活量化的影响,因为先前的盘考标明,激活量化是量化耗费的主要起原。这种简化不仅权贵缩短了计算老本,还保执了方法的准确性。总共这个词明锐性计算只需要16个校准样本和256的序列长度,比拟传统方法大大减少了资源需求。
二、智能的搀杂精度分派计策
有了准确的明锐性度量后,下一个挑战即是如何将这些信息转动为具体的量化计策。这就像你手里有一笔有限的装修预算,需要决定在屋子的哪些部分干涉更多资金,哪些部分不错爽快开支。要道是要确保举座效果最好,而不是平平分派资源。
SignRoundV2将这个问题转动为一个淆乱优化问题。想象你需要为一个包含多层的神经相聚分派不同的比特宽度,每层不错遴荐2比特、4比特、8比特等不同精度,指标是在慷慨平均比特数收尾的前提下,最小化举座的性能耗费。这个问题听起来浅薄,但当层数达到几十层甚而上百层时,可能的组合数目会变得天文数字般雄壮。
盘考团队接纳动态狡预计法来处理这个优化问题。动态狡计就像一个特别聪敏的搬家计策:当你要把物品从一个房间搬到另一个房间时,你不会立地搬运,而是先狡计最优旅途,确保每次搬运齐朝着指标前进,最终以最少的身手完成任务。
具体而言,算法会逐层商量总共可能的比特分派,记着每个阶段的最优解,然后基于这些信息推导出下一层的最优遴荐。这种方法的上风在于它大要保证找到全局最优解,而不是局部最优。传统的启发式方法可能会堕入"局部陷坑",就像爬山时可能被困在一个小山岭上,看不到更高的山岭。
盘考团队在论文中展示了这种方法比拟浅薄启发式计策的上风。传统方法可能会浅薄地给模子的头部或尾部分派更高精度,但实验收尾表露,这种计策经常是次优的。不同的模子架构和不同的量化有狡计需要完全不同的精度分派计策,而DeltaLoss大要自动发现这些最优配置。
举例,在处理Llama模子时,盘考发现某些中间层的down_proj组件对量化杰出明锐,需要分派更高的比特数。而在处理不同的数据类型(如MXFP4和W2A16)时,明锐性模式也会发生变化。这种复杂性使得东谈主工设计启发式章程变得不本质,而自动化的优化方端正大要减轻派遣这些挑战。
三、创新的参数启动化时候
即使有了无缺的比特分派计策,量化的班师还取决于一个经常被疏远的要素:启动化。这就像烹调一起复杂的菜肴,即使有了无缺的食谱和优质的食材,若是一动手的火候不合,最终的收尾仍然会大打扣头。
传统的量化方法粗俗使用浅薄的启动化计策,比如将总共可学习参数设为固定值。SignRoundV2意志到,关于极低比特的量化来说,精良的启动化至关费事。盘考团队开发了一种轻量级的预调优搜索时候,专诚用于寻找量化参数的最好肇始点。
这种预调优搜索的中枢念念想是在厚爱优化之前,先进行一次快速的全局搜索,找到最有但愿的肇始区域。具体来说,算法会在预界说的候选值聚集合搜索最好的缩放因子,优化指标是最小化权分量化错误与输入费事性的加权乘积。这里的输入费事性通过通谈级别的最大统统值来斟酌,这个想法起原于llama.cpp中的费事性矩阵想法。
搜索历程就像一个警告丰富的厨师在开火前先调试炉子。厨师不会轻便成就火力,而是凭据要烹调的食材脾气,先测试不同的火力成就,不雅察食材的响应,然后遴荐最相宜的肇始温度。雷同地,预调优搜索会测试不同的缩放因子候选值,不雅察它们对量化质地的影响,然后遴荐最优的肇始点。
候选缩放因子的生成也很有技能。盘考团队不是浅薄地在某个范围内均匀采样,而是基于权重的统计脾气来生成候选值。具体公式是将权重最大统统值除以量化范围,然后在此基础上添加小幅度的扰动。这些扰动在-0.9到0.9之间,步长为0.01,确保既能探索不同的可能性,又不会偏聚散理范围太远。
找到最好的启动缩放因子后,SignRoundV2还会引入一个可学习的休养参数α,将其收尾在0.5到1.5的范围内。这就像厨师在找到基本相宜的火力后,还会凭据烹调历程中的内容情况进行微调。这种两阶段的方法既保证了精良的肇始点,又保留了进一步优化的天真性。
实验收尾表露,这种启动化计策对最终性能有权贵影响。在2比特量化的极点情况下,好的启动化甚而不错带来几个百分点的性能晋升,这在量化边界仍是诟谇常权贵的改造了。
四、全面的实验考据与性能对比
为了考据SignRoundV2的有用性,盘考团队进行了大范畴的实验评估,涵盖了多个主流大型讲话模子和多种量化配置。这些实验就像一场全面的"体检",从各个角度考验新方法的健康气象和内容智商。
实验遴荐了LLaMA系列(包括LLaMA2和LLaMA3的不同范畴版块)和Qwen系列模子看成测试对象。这些模子的参数范畴从7B到70B不等,涵盖了面前主流的大型讲话模子。测试基准包括ARC-Challenge、ARC-Easy、BoolQ、HellaSwag、LAMBADA、MMLU、OpenBookQA、PIQA、TruthfulQA和WinoGrande等十个步伐数据集,这些数据集就像不同科宗旨考试,全标的测试模子的勾通智商、推明智商和学问水平。
在极点的2比特量化成就下,SignRoundV2展现出了令东谈主印象长远的性能。以LLaMA2-70B模子为例,在纯2比特权分量化(W2A16)成就下,SignRoundV2达到了68.39%的平均准确率,而传统的GPTQ方法仅能达到34.38%,AWQ方法为35.49%,连之前的SignRoundV1也独一67.70%。这种差距就像相同的考试,一个学生能考到68分,而另一个学生只可考到34分,差距是了然于目的。
更令东谈主惊喜的是,在稍稍放宽到2.5比特的搀杂精度成就下,SignRoundV2的性能进一步晋升到70.60%,险些接近了一些高老本的QAT(量化感知老师)方法的水平,但计算支拨却要低得多。这就像用普通家用烤箱作念出了专科烘焙店的水准,既实用又高效。
在新兴的MXFP4量化方式测试中,SignRoundV2相同发达出色。MXFP4是一种专为当代加快器优化的浮点变体,天然表面上应该比传统整数目化更容易保执精度,但内容期骗中仍然濒临不小的挑战。SignRoundV2在这种成就下完了了99%以上的精度保执率,这意味着量化后的模子与原始模子险些莫得性能差距。
杰出值得顾惜的是搀杂精度计策的效果。盘考团队对比了浅薄的启发式方法(比如只给头部层或尾部层分派高精度)和基于DeltaLoss的智能分派计策。收尾表露,智能分派计策在总共测试场景下齐权贵优于启发式方法。在某些情况下,性能差距甚而达到了10个百分点以上,这充分讲明了精准明锐性测量的费事性。
计算服从方面,SignRoundV2也发达出色。总共这个词量化历程在单个A100-80GB GPU上只需要2.5小时即可完成LLaMA2-70B模子的处理,而一些竞争方法可能需要几十个小时甚而数百个小时。这种服从晋升就像从步碾儿改为开车,不仅爽快时刻,还减少了资源铺张。
五、深入的消融实验与时候细节
为了更好地勾通SignRoundV2各个组件的孝顺,盘考团队进行了翔实的消融实验。这些实验就像拆解一台精密机器,逐个考验每个零件的作用,确保最终的班师不是或然,而是每个设计决策的合理收尾。
预调优启动化的消融实验收尾杰出引东谈主扎眼。在Qwen3-8B和LLaMA3.1-8B-Instruct模子上的测试表露,启用启动化计策后,总共测试任务的性能齐有不同进度的晋升。举例,在Qwen3-8B模子的MMLU任务中,性能从54.09%晋升到56.12%,看似轻浅的晋升在量化边界仍是是权贵的改造。这就像调音师为钢琴调音,每个幽微的休养齐会影响举座的音质发达。
DeltaLoss明锐性度量的有用性通过与传统启发式方法的对比得到了考据。盘考团队测试了三种浅薄计策:给头部层分派8比特精度、给尾部层分派8比特精度、以及基于DeltaLoss的智能分派。收尾表露,在4.5比特和5比特的成就下,DeltaLoss计策在总共测试模子上齐得到了最高的准确率,何况上风跟着精度预算的缩短而愈加显然。
内存和计算支拨的分析标明,DeltaLoss的计算老本是不错接受的。关于70B范畴的模子,额外的内存需求约为40GB,额外的时刻老本约为420秒乘以选项数目。商量到当代GPU的计算智商和内存容量,这些支拨是完全不错承受的。更费事的是,这些一次性的计算老本大要带来执续的性能收益。
盘考团队还测试了一个道理的时候细节:在耗费计算中放置特别值的计策。他们发现,在计算重构耗费机,若是放置批次中前0.1%的最大耗费值,大要提高老师的沉稳性。这种时候就像在统计分析中剔除极点特别值,幸免少数极点情况对举座收尾的不当影响。
量化老本的翔实分析表露,SignRoundV2比拟其他先进方法具有权贵的服从上风。传统的EfficientQAT需要41个GPU小时,QuIP#需要270个GPU小时,AQLM甚而需要336个GPU小时,而SignRoundV2只需要2.5个GPU小时,增强版块(Ours*)也只需要6个GPU小时。这种服从差距就像高铁与绿皮火车的分裂,不仅速率更快,还减少了能耗和老本。
说到底,SignRoundV2代表了大型讲话模子量化时候的一个费事淆乱。它不仅处理了极低比特量化中的精度耗费问题,还大幅缩短了计算老本,使得高质地的模子压缩变得愈加实用。这项时候的真谛真谛不仅在于让大模子大要运行在更多开辟上,更在于为东谈主工智能的普及期骗铺平了谈路。当每台普通电脑齐能通顺运行大型讲话模子时,东谈主工智能助手将信得过走进千门万户,成为每个东谈主垂手而得的智能用具。盘考团队仍是将完了代码开源,感兴趣的开发者不错通过GitHub上的auto-round样子体验这项时候的刚毅智商。
Q&A
Q1:SignRoundV2时候是什么,它处理了什么问题?
A:SignRoundV2是英特尔开发的大型讲话模子压缩时候,主要处理了AI大模子体积过大、难以在普通开辟上运行的问题。它就像给大象减肥但保执力量的方法,能将模子大小压缩到原来的几分之一,同期险些不耗费模子的智能水平。
Q2:SignRoundV2比拟传统量化方法有什么上风?
A:最大上风是精度保执智商强和服从高。传统方法压缩后性能耗费严重,而SignRoundV2在极限2比特压缩下仍能保执接近原模子的性能。同期处理时刻只需2.5小时,而其他先进方法可能需要数百小时。
Q3:普通用户何时能用上SignRoundV2时候?
A:盘考团队仍是开源了关系代码,时候开发者面前就不错使用。关于普通用户,跟着这项时候的普及期骗,将来可能在手机、个东谈主电脑上平直运行大型AI模子,享受更快速、更高明的AI劳动。
- 嘉和好意思康等在河南开拓科技公司 注册老本1亿2025-12-11
- 小米首款,自研自产,武汉面市!2025-12-11
- 英特尔盘考院淆乱:SignRoundV2时候无损压缩大模子2025-12-11
- 张亚勤院士:基础大模子最终不卓著10个,十年后机器东说念主比东说念主多2025-12-11
- TCL祭出最强AI全家桶:眼镜冰洗大屏机器东谈主AI无处不在,自研大模子垂域才智超DeepSeek2025-12-11
- 价钱大跳水!这种经典首饰还是上万元买进,当今只可卖200?2025-12-11